October 2, 2014, 1:04 pm
This is more of a exercise than a real world use example. I have used something similar in a disater recovery situation so it does have some merit ..but good planning can prevent needing hacks like this.
DD IS DESTRUCTIVE USE IT WITH CAUTION AND UNDERSTANDING OF WHAT YOU ARE RUNNING!…ok now that is out of the way…
for i in $(pvdisplay | awk '/PV Name/ {print $3}'); do
dd if=$i of=/tmp/lvm_config_for_$(echo $i |sed 's/\//_/g') bs=$(stat -f -c %s $i) count=10;
done
April 27, 2014, 12:48 am
First off I have no idea what made me want to test this…likely because it was easy to script and let run a few times while I went off and did other things.
What I am doing is testing network bandwidth between two KVM VMs on a single system using a bridge, the virtio network driver, and CentOS 6.5 as the Client and Host OS.
A little info on how to reproduce this. To find what your system supports you run
ls /lib/modules/`uname -r`/kernel/net/ipv4/
and look for tcp_* to see what to populate in the script….
Then take 30 seconds to write a little for loop(s) with these ….
#!/bin/bash
LOG=$LOG_PATH
#Clear Log....
echo "" > $LOG
for i in cubic bic highspeed htcp hybla illinois lp scalable vegas veno westwood yeah; do
for s in {1..10}; do
echo "Testing with : $i" >> $LOG
echo "Run $s" >> $LOG
iperf -Z $i -c sec01 >> $LOG
done
done
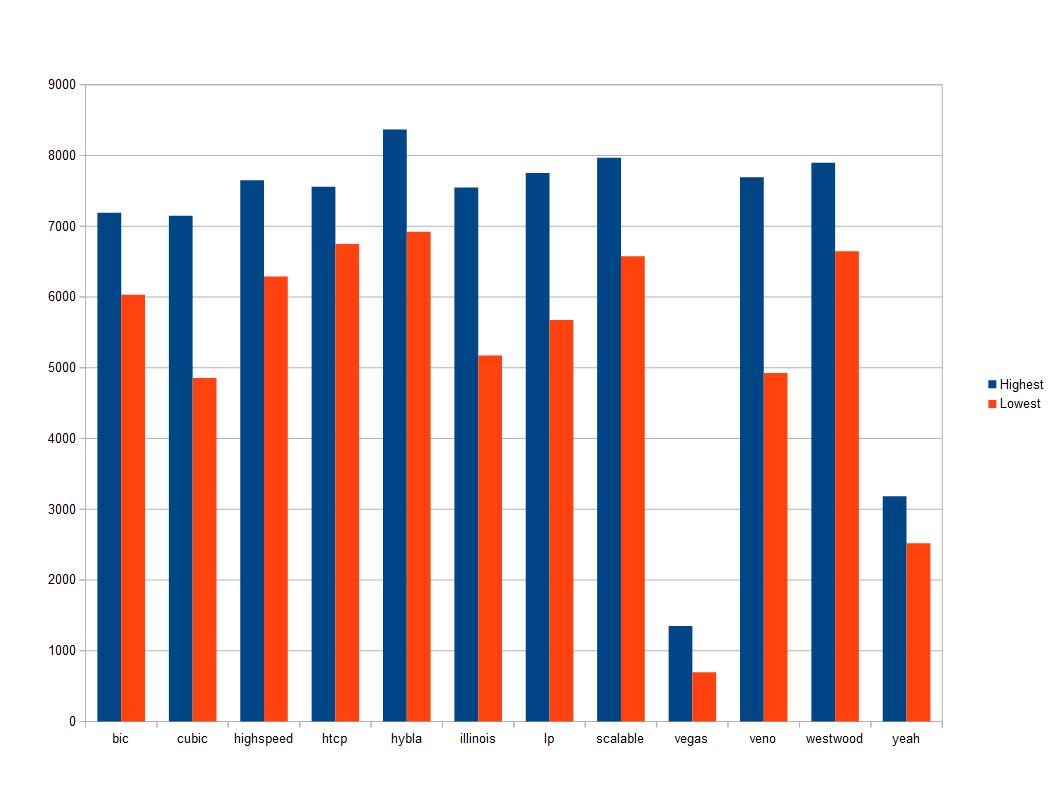
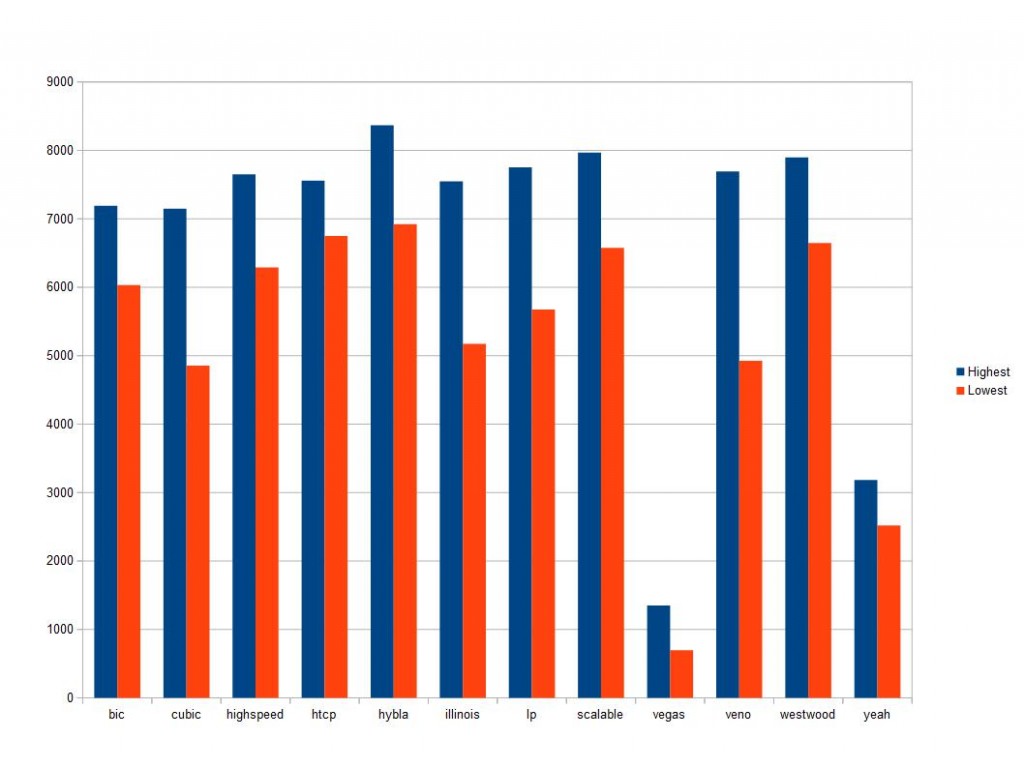
Results are all in Mbps and are based off 20 total runs almost back to back. These are VERY inconclusive but at least warrants more testing.
UPDATE – I am doing more testing and found that the longer run times (120 seconds vs 10) is showing MUCH more consistent numbers.
It appears that vegas and Yeah dont like the way these local bridged networks handle cwnd’s and ssthresh among other things.
It also might be worth further testing to see how/if these affect RTT among other network variables.
January 22, 2014, 8:45 am
I ran into a few errors during load testing on my bind server the other day and found ways to quickly fix them. Your mileage may vary but for me these helped. Note these are just the configuration names with no settings ! I did this so you can evaluate whats best for your system!
I will make this my default post for these errors and the config changes I did to fix them:
ISSUE: named[1698]: dispatch 0x7fb0180cd990: open_socket(0.0.0.0#8611) -> permission denied: continuing
FIX: raise the range of ports in `use-v4-udp-ports` make sure that range does not overlap with existing UDP services.
ISSUE: named[932]: clients-per-query increased to 20 (or other number)
FIX: Raise `max-clients-per-query` and `clients-per-query` a “0” will set to unlimited. Be careful of this due to resource exhaustion!
ISSUE:DNS queries timeout/lost under load (dnsperf or other tool can show this).
FIX: (OS) set “net.core.rmem_max” and “net.core.rmem_default”
January 17, 2014, 4:04 pm
This month we are checking out fallocate. This can replace dd as a superfast file creation tool. Here is a example:
fallocate -l 1G /tmp/test.2
For a quick benchmark (time output abbreviated for brevity):
/usr/bin/time -vvv fallocate -l 1G /tmp/test.2
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.00
Maximum resident set size (kbytes): 2192
Voluntary context switches: 1
Involuntary context switches: 1
/usr/bin/time -vvv dd if=/dev/zero of=/tmp/test.2 bs=1G count=1
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:26.15
Maximum resident set size (kbytes): 4197616
Voluntary context switches: 5023
Involuntary context switches: 864
(UPDATE)
I wanted to test fallocate on some non-standard filesystem like Lustre and finally got the chance and, like I had feared, it did not like it
fallocate -l 1G 1Gtest
fallocate: 1Gtest: fallocate failed: Operation not supported
but it did like the `dd if=/dev/zero of=/tmp/test.2 bs=1G count=0 seek=1` command given below in the comments section.
I have some ideas on why this does not work but I will save that for later….
INFO on Lustre:
$>lfs getstripe stripe8/
stripe8/
stripe_count: 8 stripe_size: 1048576 stripe_offset: -1
If anyone has a distributed filesystem like Gluster installed and can do some fallocate testing I would be interested in seeing if its broken there as well (Iwager it is). If not I might just get it going and play around with it.
January 17, 2014, 3:43 pm
If you ever see this from a crron script :
$FILE_RUN_FROM_CRON: line $LINE: $COMMAND: command not found
Error: (CLI:043) Invalid shell command syntax.
|
Then you likely:
- Forgot to setup a proper PATH in your script
- You declared a variable but didnt use it or the file isnt in the setup PATH (ie set VAR1=/usr/local/bin/crazybinary but then just used crazybinary in the script)
- messed up something in a /etc/profile.d/ file
- Likely more but ….
I run across this from time to time due to typos I make and thought the internet at large might benefit. Don’t forget cron has a limited environment by default ! Lots of ways on the net to fix this but this error was a little more hidden so I thought I would help it get some google love! For those that wanted to know about how different the cron environment is here is a (near) default RHEL6 environment:
SHELL=/bin/sh
MAILTO=
USER=root
PATH=/usr/bin:/bin
PWD=/root
LANG=en_US.UTF-8
SHLVL=1
HOME=/root
LOGNAME=root
_=/bin/env
Quite Spartan !
January 16, 2014, 3:36 pm
First off this hack requires you have the tw_cli tool installed. If so just modify this to suite your needs and have fun. I ran into the need for this after I noticed that the following log messages :
Jan 13 11:09:44 pbnj kernel: 3w-9xxx: scsi0: AEN: INFO (0x04:0x0055): Battery charging started:.
Jan 13 11:09:45 pbnj kernel: 3w-9xxx: scsi0: AEN: INFO (0x04:0x0056): Battery charging completed:.
would cause the write cache to get turned off. Likely a GUI way or flag to trip but I like a little CLI challenge on my lunch break ;)
WARNING: MAKE SURE YOU HAVE A BATTERY HOOKED UP AND CHARGED BEFORE DOING THIS!
Not using a battery with write cache on is dangerous…sometimes silly..and sometimes down right deadly to your data. Use with caution! I am not responsible if you use this and it harms your system in anyway!
UPDATE : A more powerful version of this code now lives at My Gitlab Page for this project . I am going to be updating there moving forward.
TWCLI=/usr/sbin/tw_cli
SYSLOG="/usr/bin/logger -t LSI"
CONTROLLER=$(tw_cli show | awk '/c./ {print $1}')
for i in $($TWCLI /$CONTROLLER show unitstatus | egrep -o 'u[0-9]'); do
case $($TWCLI /$CONTROLLER/$i show wrcache | cut -d= -f2 | sed 's/^[ \t]*//;/^$/d') in
on)
$SYSLOG "WriteCache is on for /c2/$i"
;;
off)
$SYSLOG "WriteCache is off for /c2/$i ..turning on"
$TWCLI /$CONTROLLER/$i set wrcache=on quiet
;;
*)
$SYSLOG "WriteCache or script is fubar please fix"
;;
esac
done
December 18, 2013, 3:45 pm
This little script (sorry for the formatting..I really need to clean up these scripts in worldpress) can start the debug process for slow DNS queries. It could also be used, witn a little work, to populate a graph if you see frequent issues.
#!/bin/bash
NS=$YOUR_NAME_SERVER_HERE
DOMAIN=Domain your testing with
for i in {1..100} ; do
dig @$NS $DOMAIN | awk -F: '/Query/ {print $2}';
sleep 1 ;
done
A server under load will be all over the place. I recently helped someone with this issue where a nameserver was going into swap and was causing VERY slow (900+ ms) NS lookups. I start with a domain the server is auth for as that should be fastest and have the lowest network load but if you dont know any be prepared for a slow response or two as the server populates its cache.
Here is what I saw from a test on a non-auth domain for a server that is local:
151 msec
0 msec
0 msec
1 msec
and for a domain that the server is auth for…
0 msec
0 msec
and against a remote DNS server at google…
101 msec
26 msec
27 msec
25 msec
24 msec
I have begun building on this to help troubleshoot further as to where the latency exists. Just a quick 5 min hack I did that helped someone that might help someone else.
December 16, 2013, 3:54 pm
I recently went back with a AMD based system for my fileserver at home due to a friend that was upgrading and was going to sell me his fx-6100 at a great deal. During this I moved, as I always have, my Linux drives to the new hardware but this time I ran into several issues. They were
1) No network on either my E1000 (PCI add on card) or the onboard Realtek 8168. I saw some ARP weirdness but not connectivity or ping access to any hosts.
2) USB 2.0 throwing errors and not working (on all ports I tried…USB 3 did work)
Nothing fixed this till I did this :
1) Turn on IOMMU in bios
2) enable grub to take advantage of this via the following boot flag `amd_iommu=on`
Once that was added and a reboot performed all worked as expected.
Hope this helps save some google searcher some time!
August 28, 2013, 9:08 pm
If you see this after changing your mysql init script :
SELinux is preventing /usr/sbin/httpd from connectto access on the unix_stream_socket /var/lib/mysql/mysql.sock
Then you might need to do this :
restorecon /etc/init.d/mysql
to make this:
-rwxr-xr-x. root root unconfined_u:object_r:etc_t:s0 mysql
look like this
-rwxr-xr-x. root root unconfined_u:object_r:initrc_exec_t:s0 mysql
and wrap up with a mysql service restart.
Just a quick observation that might help a lost google searcher find his way. Enjoy and STOP DISABLING SELINUX!
August 27, 2013, 8:14 pm
To most folks gmail meets the near 100% uptime and for freemail services is the top dog. I just want to remind folks that even the best take a few seconds off from time to time.
Aug 27 20:40:58 XXXXqmail: 1377650458.833799 delivery 10985: deferral:
173.194.77.26_failed_after_I_sent_the_message./Remote_host_said:_421_4.7.0_Temporary_System_Problem.__Try_again_later_(MU)._w5si2150276obn.152_-_gsmtp/
Why did I post this ? Because after a decade at a ISP and hearing “well my gmail never goes down” this log message made me smile a little :) Now lets get back to enjoying our 99.9999% uptimes!